배열로 push_swap 해보자! (2)

“push_swap에 대하여”
1. 추상화 프로그래밍
- push_swap (1)에서 말한 바 있듯이 배열로 push swap을 진행하기 위해서는, 그 배열이 마치 원형 큐(Circular Queue)나 덱(Deque)과 같이 움직여야 하며, 가변하는 size의 정보를 담을 수 있어야 한다.
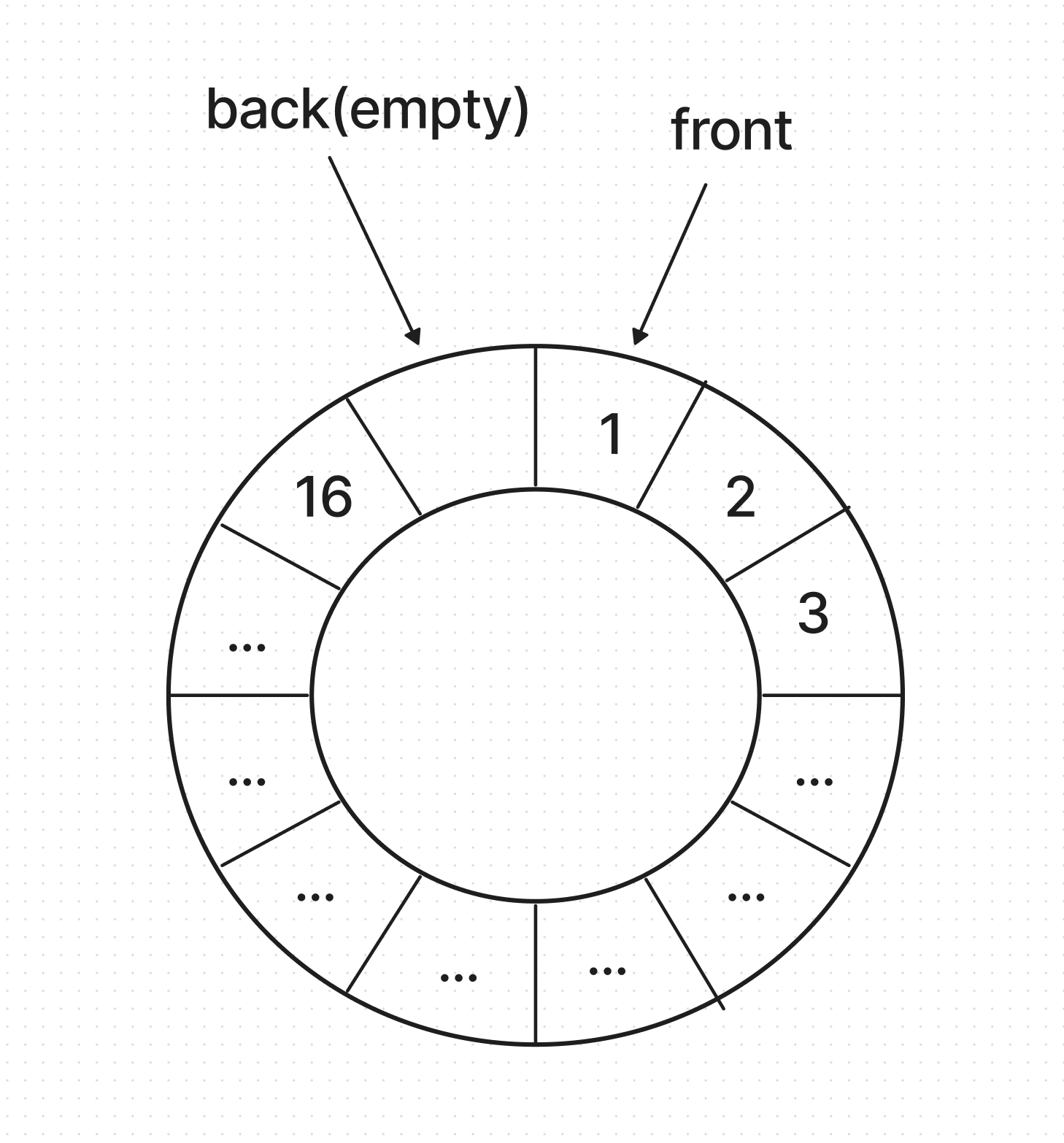
- 이런 새로운 형태의 배열을 구현하는 것에 있어 가장 중요한 것은 추상화라고 한다. 나는 추상화 프로그래밍이라는 개념을 이때 처음 알게 되었다. 이것이 말로 설명하기 참 오묘한데, 지금부터 시작해보도록 하겠다.
2. 추상화된 새로운 배열 mk2
- 추상화되어 구현된 새로운 배열은 분명 우리가 원래 알고 있는 배열과 작동 방식이 조금 다르다. 원래 배열의 틀에서 벗어나야 한다.
새로운 배열을 구성하는 구조체의 요소들에 대한 설명
// 구조체
typedef struct s_deque
{
int *arr;
int head;
int tail;
int size;
int capacity;
} t_deque;
...
(1) int* arr / int capacity
- 숫자들을 담아두고 있는 배열이다. arr의 len은 항상 capacity와 동일하다. 처음 구조체를 할당할 때부터 아래와 같은 식으로 할당한다.
(할당 예시)
...
a->capacity = 8;
a->arr = (int *) malloc(sizeof(int) * a->capacity); // capactiy -> arr의 len
...
원래 배열의 틀에서 벗어난다는 것은 이 arr 자체가 스택 a 혹은 b가 아니라는 점을 이해하는 것이다. 배열은 스택을 메모리 저장시켜두기 위한 그릇일 뿐이고, 스택은 배열 위에서 추상적으로 작동한다. 배열의 모든 값이 스택에 포함되지 않을 수 있으며, 배열의 인덱스 자체는 스택의 인덱스와는 다르다(배열의 첫 번째 값이 스택의 head 값이 아닐 수 있으며 배열의 마지막 값이 스택의 tail 값이 아닐 수 있다.). 스택에 포함되지 않은 배열 arr의 값들은 모두 쓰레기 값으로 연산에 어떠한 영향력도 행사할 수 없게 된다. 이 부분에 대해서는 나중에 계속해서 이야기할 것이다.
capacity는 처음에는 고정된 값으로 초기화되지만, 스택에 원소들이 계속 push 되어서 원소들의 개수가 capacity 이상으로 늘어나게 되면 2배로 늘어나게 되고, 스택에 원소들이 계속 pop 되어서 원소들의 개수가 현재 capacity의 1 / 2 이하로 줄어들게 되면 2분의 1로 줄어든다. 스택의 원소 개수가 바뀔 때마다 capacity를 바꾸어 새로 배열을 할당하면 계산량이 너무 많아질 것이다.
(2) int head
- 스택의 top의 원소의 인덱스를 의미한다. 따라서
t_deque a의int arr[head]는 스택 a의 top의 원소를 의미한다. head는 0이 아닐 수 있으며 가변하는 요소이다!. swap a를 하게 된다면, arr[head]와 arr[head + 1]의 원소를 swap하게 될 것이다. 배열의 앞에서도, 뒤에서도 원소를 push 혹은 pop할 수 있기 때문에 head가 스택의 top이라는 사실을 인지하고 있지 않으면 스택의 앞뒤를 헷갈리기 쉽다.
(3) int tail
- 스택의 bottom에 있는 원소의 인덱스 + 1를 의미한다(문자열의 NUL Terminating처럼 마지막 값을 비워둔다고 생각하면 편하다). 따라서
t_deque a의int arr[tail - 1]는 스택 a의 bottom에 있는 원소를 의미한다. tail은 arr의 len이 아닐 수 있으며 가변하는 요소이다!. 배열 내의 arr[head] 값부터 arr[tail - 1] 값만이 스택에 속하게 된다.
(4) int size
- 스택의 길이를 의미한다. size는 배열 arr의 길이(capacity)가 아니다. 예를 들어 스택 a(t_deque a)에서 스택 b(t_deque b)로 push가 일어났다고 해보자. 구조체
t_deque a의 size는 1 줄어들지만 size가 capacity의 2분의 1보다 작아지지 않는다면 a의 arr 길이(capacity)은 변하지 않는다. 마찬가지로t_deque b의 size는 1 늘어나지만 size가 capacity보다 커지지 않는다면 b의 arr 길이(capacity)는 변하지 않는다.
사용 예시, pop_back()
- 예를 들어,
t_deque a의 구조체가 아래와 같다고 하자. arr에 있는 ‘-‘는 쓰레기 값을 의미한다. 초기 capacity를 8로 정하고, 인자 7개(1, 2, 3, 4, 5, 6, 7)로 push_swap을 실행한다면 다음과 같이 초기화될 것이다.
./push_swap 1 2 3 4 5 6 7
초기 capacity = 8; // int *arr의 len
int *arr = {1, 2, 3, 4, 5, 6, 7, -}; // int *arr;
index = 0, 1, 2, 3, 4, 5, 6, 7 // 배열 arr의 idx
↑ ↑
head tail
head = 0 // arr[head] = 1;
tail = 7 // arr[tail - 1] = 7;
** 추상화된 stack a -> {1, 2, 3, 4, 5, 6, 7} **
stack a의 size = 7 // {1, 2, 3, 4, 5, 6, 7}의 7개
- 구조체의 배열 arr는 8칸짜리 배열이지만, a 스택의 원소의 개수는 실제로 7개다. 스택의 첫 번째 원소는 1이고, 그 인덱스는 배열 상 0(head)이다. 스택의 마지막 원소는 7이고, 그 인덱스는 6(tail - 1)이다. 우리는 배열 내의
arr[head]값부터arr[tail - 1]값만을 스택으로 간주한다. 배열은 원소들을 담기 위한 그릇일 뿐이고 스택은 추상화되어 다른 방식으로 움직인다. 스택을
pop_back()해서 맨 뒤의 값을 제거했다고 생각해보자. 스택은{1, 2, 3, 4, 5, 6}이 되어야 할 것이고, head는 그대로, tail은 6, size는 6이 되어야 할 것이다. 어떻게 해야 할까? 새로 6개 짜리 배열을 선언하고 원래 배열을 해제해야할까? 그러지 않아도 된다. tail을 하나 빼는 것으로 간편하게 pop_back을 구현할 수 있다. 이것이 추상화된 배열의 강력함이다. 아래를 보자.-> tail을 7에서 6으로 변경
초기 capacity = 8; // int *arr의 len
int *arr = {1, 2, 3, 4, 5, 6, 7, -}; // int *arr;
index = 0, 1, 2, 3, 4, 5, 6, 7 // 배열 arr의 index
↑ ↑
head tail (7에서 6으로 변동)
head = 0 // arr[head] = 1;
tail = 6 // arr[tail - 1] = 6;
** 추상화된 stack a -> {1, 2, 3, 4, 5, 6} ** // 스택에서 pop back된 7
stack a의 size = 6 // {1, 2, 3, 4, 5, 6}의 6개
- 아무런 데이터도 해제하거나 할당하지 않고 그저 tail 값을 7에서 6으로 바꾸기만 했다. 이는 아까 말했듯이 배열의 arr[head] 값부터 arr[tail - 1]만을 스택에 속하도록 했기 때문에 가능한 일이라 볼 수 있다. tail이 하나 당겨짐으로써 ‘-‘에 이어, ‘7’도 쓰레기 값이 되었다. 메모리 상에 존재하기는 하지만 우리가 스택으로 보는 스코프(
arr[head]~arr[tail - 1]) 바깥으로 나갔기 때문에 계산에 어떠한 영향도 미치지 못하는 쓰레기값으로 간주한다. 이것이 pop이다. 이어서pop_front()도 봐보도록 하자.
사용 예시, pop_front()
-> head를 0에서 1로 변경
초기 capacity = 8; // int *arr의 len
int *arr = {1, 2, 3, 4, 5, 6, 7, -}; // int *arr;
index = 0, 1, 2, 3, 4, 5, 6, 7 // 배열 arr의 idx
↑ ↑
head(0 -> 1) tail
head = 1 // arr[head] = 1;
tail = 6 // arr[tail - 1] = 6;
** 추상화된 stack a -> {2, 3, 4, 5, 6} ** // 스택에서 pop front된 1
stack a의 size = 5 // {2, 3, 4, 5, 6}의 5개
- 마찬가지로 아무런 데이터도 해제하거나 할당하지 않고 그저 head 값을 0에서 1로 바꾸기만 했다. 우리의 스코프(
arr[head]~arr[tail - 1]) 바깥으로 벗어난 데이터인 1도 쓰레기 값이 되었다. 이미 pop된 데이터에 우리가 굳이 신경을 써줄 필요는 없다.
결론
추상화
- 예시를 들어 새로이 추상화된 배열에 대해 설명해보았다. 어떤 식으로 작동하는지에 대해서 감이 잡혔을 지 모르겠다. 결론적으로 말하자면 새로운 배열에서 push, pop, rotate와 같은 동작의 경우 할당된 Capacity위에서 해당하는 인덱스에 인자를 넣거나, 인덱스를 옮기기만 하면 되기 때문에 간편하다(연결 리스트로 push, pop, rotate 시키는 것보다는 간편할 것이다).
- 뒤에서 선보일
push_front(),pop_front(),push_back(),pop_back(),empty(),size()등등의 함수는 추상화의 결과물들이다. 추상화의 장점은 이 함수들의 내부 구현을 정확히 알지 못하더라도 추상화된 자료 구조를 쉽게 사용할 수 있다는 점이다(물론 과제하려면 알고 있어야겠지…?). 이는 상당히 강력한 부분이라고 할 수 있겠다.
연결 리스트와의 비교
배열의 두드러지는 특징은 index 기반 접근이 가능하다는 점이다. 마찬가지로 배열로 스택을 구현했을 경우, 스택의 원소에 index 기반 접근이 가능하다. 즉 n번째 인덱스의 원소를 O(1)에 구해낼 수 있다는 점이다. 이는 연결 리스트가 따라오기 힘든 부분이다. 연결 리스트는 n번째 인덱스의 원소를 구하기 위해 n번의 연산을 해야 한다(n번째 노드를 찾기 위한 O(n)의 연산).
여담으로 c++의 deque(양방향 연결 리스트)또한 배열과 같이 접근 가능하도록 구현되어 있다(deque[n]). 뒤의 설명 글들에서는 본격적으로 함수들에 대해 설명할텐데, c++의 배열 구현과 유사한 점을 찾을 수 있을지도 모르겠다.