배열로 push_swap 해보자! (3)

“push_swap에 대하여”
초기화
typedef struct s_deque
{
int *arr;
int head;
int tail;
int size;
int capacity;
} t_deque;
...
- push_swap (2)에서 위 구조체의 각각의 구성 요소들에 대해 알아본 바 있다. 이제 직접 만들어보자.
t_deque *make_deque(void)
#include "push_swap.h"
t_deque *make_deque(void)
{
t_deque *ret;
ret = (t_deque *) malloc(sizeof(t_deque));
ret->size = 0;
ret->head = 0;
ret->tail = 0;
ret->capacity = 32;
ret->arr = (int *) malloc(sizeof(int) * ret->capacity);
return (ret);
}
배열의 정보가 들어있는 구조체 하나를 할당하고 반환하는 함수이다. 스택 하나당 구조체 하나로, push_swap의 경우 두 번의 make_deque로 진행한다(a, b). 그 이상의 구조체는 필요 없다.
초기 capacity의 경우 32개로 잡았다. 인자가 32개보다 많아지면 2배씩 늘어나고(64, 128 …), 16개보다 적어지면 2분의 1씩 줄어든다(16, 8 …). 꼭 32로 시작하지 않아도 괜찮다.
- 예시 코드
int main(int argc, char **argv) { t_deque *a, *b; // ... handle exception a = make_deque(); b = make_deque(); // ... sort, delete arguments return (0); } 인자 7개(1, 2, 3, 4, 5, 6, 7)로 stack a를 초기화 할 경우, 아래와 같다. 지난 글에서는 capacity 8로 초기화하는 예시를 보여주었지만, 이번에는 capacity 32로 초기화했다.
- 대략 이런 느낌
#include "push_swap_h"
int main()
{
// ... implementation
t_deque* a = make_deque();
int i = 1;
while (i < 8)
push_back(a, i++);
// ... implementation
}
t_deque a = {
size = 7;
head = 0;
tail = 7;
arr = {1, 2, 3, 4, 5, 6, 7, -, -, -, ... , -} // len = 32
↑ ↑
head tail
// 7개만 스택에 포함되고 나머지 25개는 쓰레기 값이다.
capacity = 32;
}
- 이미 감이 오겠지만, 스택의 top 원소는 1(
arr[head])이고 bottom 원소은 7(arr[tail - 1])이다. 우리는 arr[head]부터 arr[tail - 1]까지만을 스택으로 간주한다. 여기다가 8을push_back()하려면 어떻게 하면 좋을까?
-> push_back(a, 8);
arr = {1, 2, 3, 4, 5, 6, 7, 8, -, -, ... , -} // len = 32
↑ ↑
head tail
head = 0;
tail = 8;
size = 8;
- 이런식으로 tail을 하나 밀고, arr[tail - 1]을 8로 바꾸고, size을 하나 늘리면 되지 않을까? 너무너무 간단하다. 뒤에서 더 자세하게 살펴보자.
구조체의 정보 반환
getter를 getter라 부르지 못하고… (C길동)
- 구조체의 정보를 반환받기 위한 함수들이다. 구조체 멤버 변수에 접근하여 정보를 반환받는다.
(1) int size(t_deque *a)
int size(t_deque *a)
{
return (a->size);
}
- 구조체 a의 스택 사이즈를 반환받는다.
(2) int empty(t_deque *a)
int empty(t_deque *a)
{
return (size(a) == 0);
}
- 스택 a가 비어있으면 1을 반환하고, 그렇지 않다면 0을 반환한다. 사이즈가 0이라는 것은 스택이 비었다는 것이지, 배열 arr이 비어있다는 것이 아니다.
(3) int front(t_deque *a)
int front(t_deque *a)
{
return (a->arr[a->head]);
}
- 스택 a의 첫 번째 원소(
arr[a->head])를 반환받는다(스택의 top이다). 알다시피a->head는 0이 아닐 수 있으며, 스택 a의 첫 번째 원소는 배열 a의 첫 번째 원소(arr[0])가 아닐 수 있다.
(4) int back(t_deque *a)
int back(t_deque *a)
{
if (a->tail == 0)
return (a->arr[a->capacity - 1]);
else
return (a->arr[a->tail - 1]);
}
스택 a의 마지막 원소(
arr[tail - 1])를 반환받는다(스택의 bottom이다). 마찬가지로a->tail은 arr의 길이 len(capacity)이 아닐 수 있으며, 스택 a의 마지막 원소는 배열 a의 마지막 원소arr[capacity - 1]가 아닐 수 있다.분기문이 눈에 띈다.
a->tail == 0인 경우가 있다. 물론 a->tail이 0이 될 수 있다!! 스택 a의 마지막 원소는 항상 arr[tail - 1]이라고 했는데, 그렇다면 배열의 -1번째 인덱스를 반환받을까? 그런 경우엔 배열의 -1번째 인덱스의 원소를 찾는게 아니라,capacity - 1번째 인덱스의 원소를 반환받는다.- 아래 코드를 보자
arr = {-, -, -, ..., 1, 2, 3, 4, 5, 6, 7} // len, capacity = 32 ↑ ↑ ↑ tail(0) head(25) capacity - 1(31) capacity = 32; head = 25; // arr[25] = 1; tail = 0; // a[capacity - 1] = 7; ** 추상화된 stack a -> {1, 2, 3, 4, 5, 6, 7} ** 스택 a의 size = 7 // {1, 2, 3, 4, 5, 6, 7}의 7개 좀 의아스런 모양을 하고 있는 스택이다. 배열의 고정된 틀에서 벗어날 시간이다. 스택은 배열 위에서 추상적으로 움직이고, 우리는 arr[head]부터 arr[tail - 1]만을 스택으로 간주한다고 했다. 코드의 진행 여하에 따라 충분히 저런 모양이 나올 수 있다.
- 그림을 그려보자.
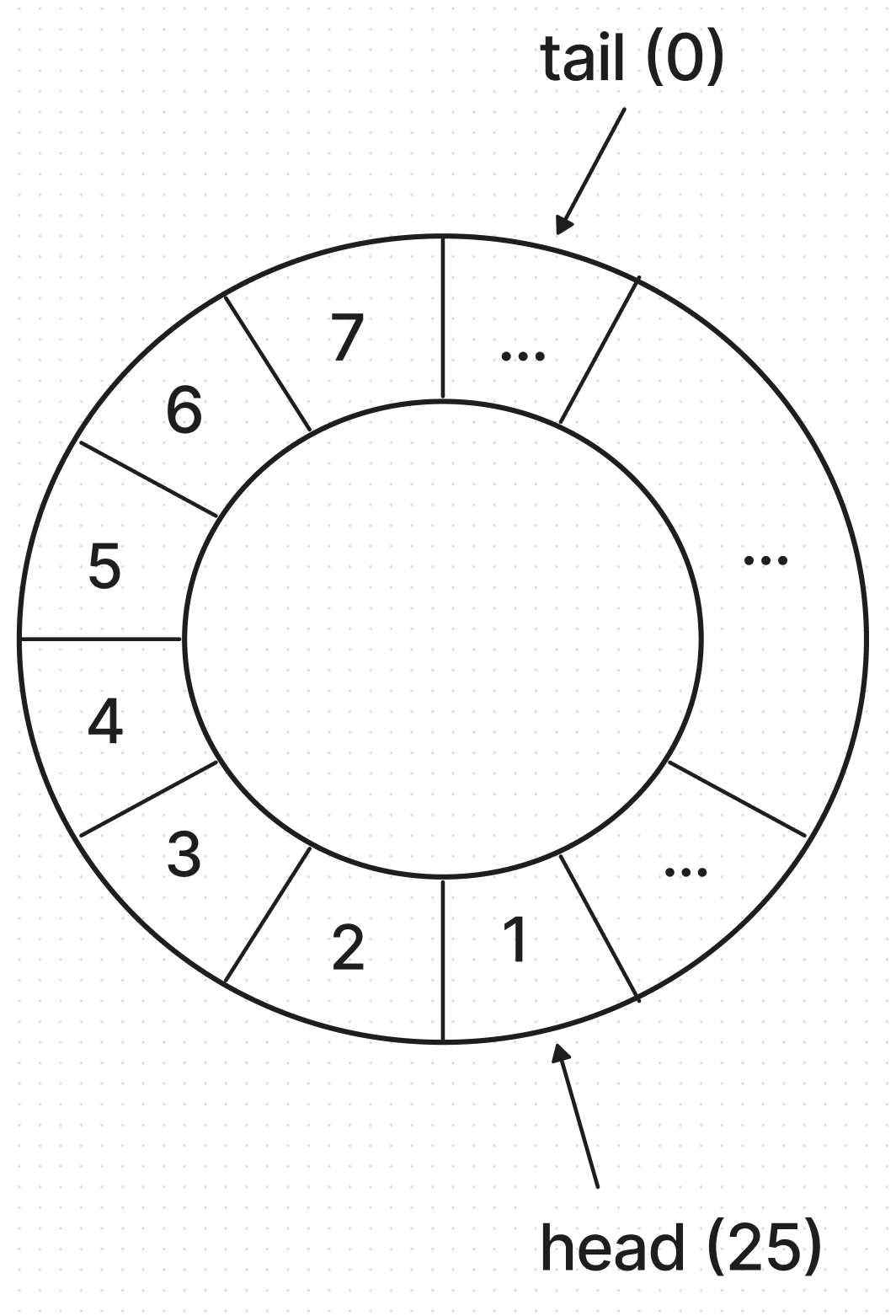
tail과 head 뒤의 숫자는 위의 코드에도 적혀있듯이, 배열 상에서의 index를 의미한다. 위 원형 큐에서 7은
arr[32(capacity) - 1]번째 원소이다. tail이 0일 때,int back()은arr[capacity - 1]번째 원소를 반환하는 것이 원형 큐의 작동이다.이렇게 보니 확실히 배열의 틀에서 벗어난 것 같다. 배열의 arr[0]이나 배열 자체의 길이는 이 그림에서 아무런 의미를 가지고 있지 않다. 우리는 다만 arr[head]에서 arr[tail - 1]만을 스택으로 간주한다. tail이 0인 경우는 예외 사항으로, 이 경우에만
tail - 1은 -1이 아니라capacity - 1이 된다.- 여기서 8을
push_back()해본다면 어떨까? 아래를 보자."t_deque* a의 정보" arr = {8, -, -, ..., 1, 2, 3, 4, 5, 6, 7} // len, capacity = 32 ↑ ↑ ↑ tail(1) head(25) a[31] capacity = 32; head = 25; // arr[25] = 1; tail = 1; // a[capacity - 1] = 8; ** 추상화된 stack a -> {1, 2, 3, 4, 5, 6, 7, 8} ** 스택 a의 size = 8 // {1, 2, 3, 4, 5, 6, 7, 8}의 8개 int b = back(a); // arr[tail - 1] = 8; - 바로 이거다. tail을 하나 더하고, tail 바로 앞의 원소를 8로 변경하고, 스택의 size를 하나 늘렸다. 그림을 보자.
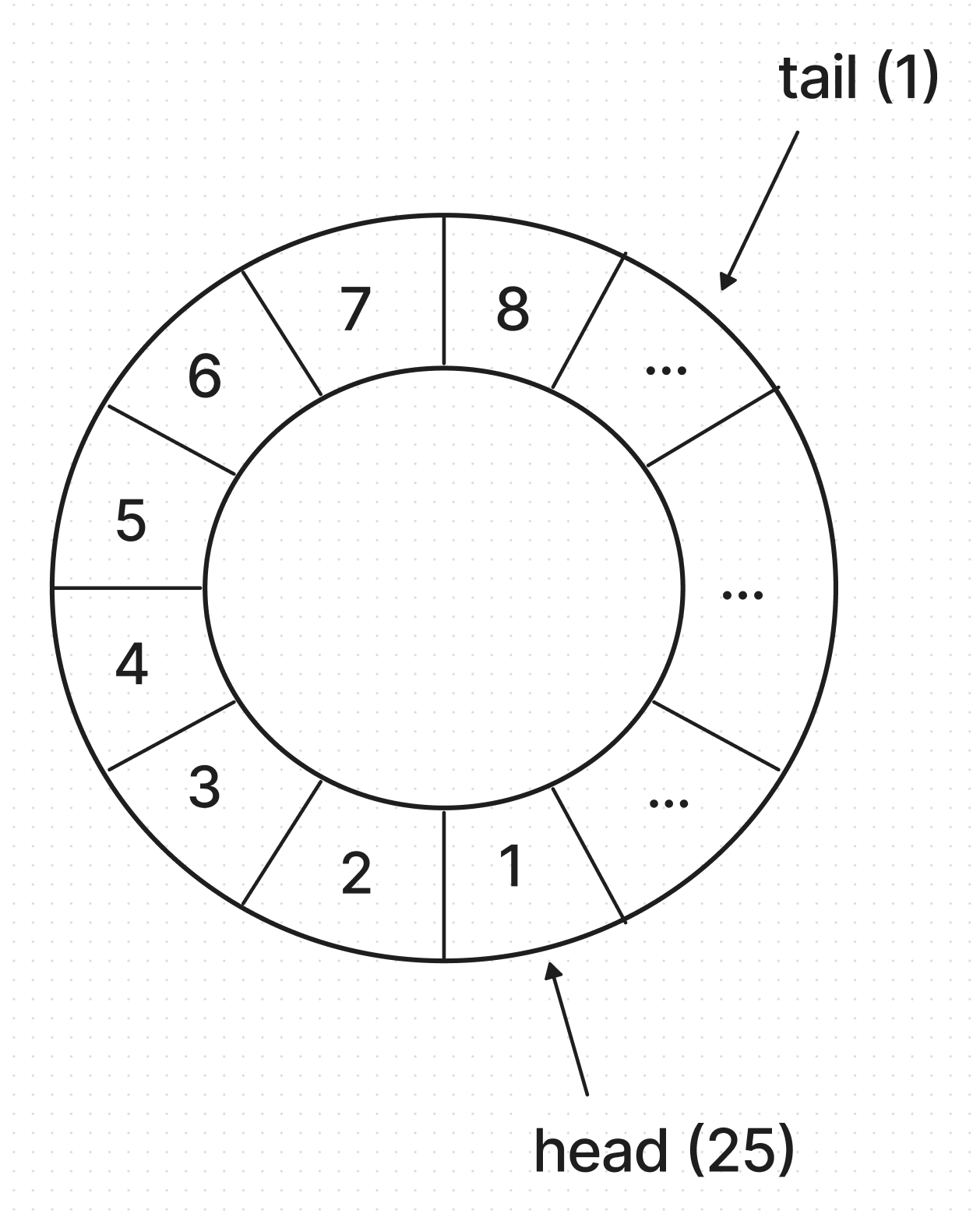
- 7 다음이 8이다. 배열 상에서는 7 다음의 원소가 없기 때문에 7을 스택의 끝으로 착각할 수 있지만, 우리의 추상화된 배열은 마치 원형 큐와 같이 동작하기 때문에 7 다음은 없는게 아니라 8이 된다. 기존 배열의 틀에서 벗어나자. a[capacity(32) - 1] 다음은 a[0]이다. 그리고 우리는 arr[head]부터 arr[tail - 1]만을 스택으로 간주한다.