[구글 머신러닝 부트캠프 2024] Gemma Sprint, Gemma2를 파인튜닝 해보자
![[구글 머신러닝 부트캠프 2024] Gemma Sprint, Gemma2를 파인튜닝 해보자](/assets/img/ml/gemmasprint/huggingface.webp)
- Gemma 스프린트 프로그램 (Gemma Sprint Program)
- Reference
- 개발 환경
- 주제
- (1) 환경 설정
- (2) 모델 사용해보기
- (3) 모델 파인튜닝 해보기
- (4) Hugging Face 배포 및 Test Code 작성
- (5) 마무리
Gemma 스프린트 프로그램 (Gemma Sprint Program)

Gemma Sprint는 구글 머신러닝 부트캠프 2024를 수료하기 위한 새로운 조건이다. 작년에는 TensorFlow 자격증을 취득하는 코스가 있었던 것 같은데, 이번에는 Gemma2를 이용하여 프로젝트 결과물을 만드는 Gemma Sprint가 새로운 수료 조건이 된 것으로 보인다.
Sprint를 진행할 수 있는 방법은 첫 번째로 Kaggle Models 혹은 Hugging Face Models에 파인튜닝한 Gemma 모델을 배포하고 Kaggle Code (Notebook) / Hugging Face Model Card에 모델 설명, 모델 학습 과정, 코드, 성능/결과 등을 함께 작성하는 것이고, 두 번째로 GitHub, Google Colab, Jupyter Notebook 등에 코드를 기록하고, 블로그 또는 YouTube로 튜토리얼을 제작하는 것이다. 2개를 전부 하는 것도 권장 사항으로, 본인의 경우 Kaggle에 모델을 배포하였고, 그 과정을 블로그에 튜토리얼로 남기려 한다.
Reference
- Gemma2 모델을 Fine Tuning 하는 과정은 위 사이트를 정말 많이 참고했다. 애초에 LLM/FineTuning에 대한 정보가 전무한 상태로 들어왔기 때문에, 위 글이 없었다면 이번 Gemma Sprint를 진행하기가 쉽지 않았을 것으로 생각한다.
압도적감사
개발 환경
- 아직 머신러닝용 데스크탑을 마련하지 못해서 Google Colab을 사용하고 있었기 때문에 Gemma Sprint도 주로 Colab을 이용하는 것으로 진행하였다. 같은 회사의 서비스여서 그런지, Colab에서는 HuggingFace를 써서 아주 빠르고 간편하게 Gemma2 모델을 호출하고 튜닝할 수 있다.
- 마찬가지로 Kaggle을 이용해서도 Gemma2 모델을 로드하여 튜닝할 수가 있다. Gemma2는 Kaggle에서 제공하는 Gemma2의 Model Card로, 여기서 새로운 Notebook을 만들어 모델을 input으로 받아올 수가 있다. Kaggle의 경우 일주일에 GPU를 30시간, TPU를 20시간 제공하는데 Colab에 컴퓨팅 단위를 다 쓰고 새로운 컴퓨팅 단위를 구매하기까지 부족한 시간에 캐글에서 코딩을 했으나 메모리 부족 이슈를 해결하지를 못해 결국 Colab으로 프로젝트를 마무리할 수 밖에 없었다.
주제
- 우리 팀의 Projects Description은 아래와 같다.
The project develops a system that automatically generates the full content of academic abstracts
based on their summaries. The tool aims to enhance research efficiency by providing a complete
version of the abstract from concise summaries.
즉, 논문 abstract의 Summary와 그 원본 글(Original)을 학습시켜서, 특정 주제에 대한 Summary를 제공했을 때 새로운 초록을 생성하는 모델을 파인 튜닝하는 것이 우리 Project의 목표이다.
Write My Paper!,
챗지피티나 Gemma같은 LLM이 내가 대학생일 때 있었다면 기술복제시대의 예술작품에 관한 리포트를 쓸 때 그런 고생은 하지 않았을텐데…
(1) 환경 설정
[1 - 1] 구글 드라이브 임포트
from google.colab import drive
drive.mount('/content/drive')
- 부트캠프를 진행하면서 15Gb던 구글 드라이브 용량을 졸지에 100Gb까지 늘렸다. 데이터셋 용량을 생각하면 더 늘려야할 수도 있겠다고 생각한다. 이 라인을 실행해서 드라이브에 있는 데이터셋을 Colab Notebook에 로드할 수 있다.
[1 - 2] 라이브러리 설치 및 모듈 임포트
!pip3 install -q -U transformers # 트랜스포머로 Train 실행
!pip3 install -q -U datasets # 데이터셋
!pip3 install -q -U peft # 파인튜닝(parameter efficient fine-tuning)
!pip3 install -q -U trl # 모델 학습
!pip3 install -q -U accelerate
!pip3 install -q -U bitsandbytes # 양자화를 위한 bitsandbytes
import torch
from datasets import Dataset, load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, \\
BitsAndBytesConfig, pipeline, TrainingArguments
from peft import LoraConfig, PeftModel, get_peft_model
from trl import SFTTrainer
[1 - 3] HuggingFace Login
from huggingface_hub import notebook_login
notebook_login()
- Gemma 모델을 HuggingFace를 통해 사용하기 위해서는 HuggingFace에 계정을 만들고, Model에 접근 가능한 token을 발행해야 한다. token을 발행한 후 Model에 접근 가능하도록 설정을 해줘야 하는데, HuggingFace를 써보는 것도 처음이어서 많이 헷갈렸던 기억이 있다. 설정을 하지 않으면 모델을 호출했을 때 Permission Error가 발생하게 된다.
[1 - 4] 데이터셋 로드
- 논문 abstract의 Summary - Original 쌍 Dataset은 aihub의 데이터셋을 사용했다.
- json 파일을 사용했기 때문에, python에서 json을 로드하여 pandas Dataframe으로 만들고, 본격적으로 파인 튜닝을 진행할
SFTTrainer(Supervised Fine-Tuning Trainer)에 매개 변수로 사용할 Dataset으로 만드는 과정을 거쳤다.
import json
import pandas
# Json 데이터 로드
path = '/content/drive/train_paper.json'
with open(path, 'r', encoding='utf-8') as f:
data = json.load(f)
# 데이터를 담을 리스트 초기화
documents = []
# 데이터 파싱
for item in data[0]['data']: # 리스트에 들어있는 객체 파싱
doc = {
'category': item.get('ipc', ''),
'title': item.get('title', ''),
'summary': ' '.join([summary['summary_text'] for summary in item.get('summary_entire', [])]),
'original': ' '.join([summary['orginal_text'] for summary in item.get('summary_entire', [])])
}
documents.append(doc)
- documents는 doc 객체를 원소로 하는 Python 리스트이다. 이대로는 사용할 수가 없고, pandas dataframe으로 변환하는 과정을 거쳐야 한다.
df = pd.DataFrame(documents)
print(df.shape) # (288174, 4)
df.head()

from sklearn.model_selection import train_test_split
train_df, val_df = train_test_split(df, test_size=0.1, random_state=42)
sklearn의train_test_split를 사용하면 dataset을 train set과 validation set으로 분할할 수 있다. 분리된 validation set의 경우, SFTTrainer에서 제공하는 early stopping 콜백 함수를 사용하기 위한 검증 세트로 사용하려고 했으나 Kaggle과 Colab 모두에서 CUDA 메모리 초과 문제(CUDA OOM)가 발생해서 실제로 validation set을 활용하지는 못했다. 이 부분 때문에 예상 외의 추가 지출이 발생해서 소극적으로 움직일 수 밖에 없었던 것이 아쉽다.Hugging Face에서는 Pandas Dataframe을 SFTTrainer에서 사용할 수 있는 Dataset으로 변환할 수 있는 메서드를 제공한다. From in-memory data를 참고할 것.
from datasets import Dataset
# pandas 데이터프레임을 Trainer에서 사용하기 위한 dataset 모양으로 변경
dataset = Dataset.from_pandas(df)
print(dataset)
print(dataset[0])
from_pandas를 통해 반환된 dataset은 ‘category’, ‘title’, ‘summary’, ‘original’의 피쳐를 가진 80000행의 자료구조이다.
dataset의 원소가 가진 key들 중에서 실제 훈련에 사용된 것은 ‘summary’와 ‘original’이다. summary-original 쌍을 훈련시킴으로써 새로운 summary가 주어졌을 때, original을 생성해내도록 하는 것이 궁극적인 목표이다.
# dataset
Dataset({
features: ['category', 'title', 'summary', 'original'],
num_rows: 80000
})
# dataset[0]
{
'category': '인문학',
'title': '중세시대의 對句 학습과 문학 교육',
'summary': '對句의 영역은 다양하고, 그 원리는 짝짓기이다.
하나의 텍스트가 같은 분포도를 보이는 것은 자연스럽다.',
'original': '짐작할 수 있는 것처럼, 對句의 영역은 음운, 단어, 어구, 시편의 차원에서 다양하게 이뤄지고 있으며, 그 원리는 짝짓기이다.
하나의 텍스트는 음운으로부터 텍스트 자체까지에 이르는 위계적 양상을 보이므로 對句의 영역 또한 같은 분포도를 보이는 것은 퍽 자연스럽다.
문제는 텍스트의 전 영역에 걸쳐 짝을 만들어야 한다는 강박증이다. 왜 한시학은 짝짓기에 집착하는가?'
}
[1 - 5] Hugging Face Login 및 Model Load
- 위에서 로그인을 마쳤다면 다시 할 필요는 없다.
from huggingface_hub import notebook_login
notebook_login()
BASE_MODEL = "google/gemma-2b-it"
# huggingface로부터 gemma-2b-it 모델을 받아옴
model = AutoModelForCausalLM.from_pretrained(BASE_MODEL)
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL)
Hugging Face에 계정에 모델에 접근할 수 있는 Access Token을 발행해두고, notebook_login을 통해 로그인에 성공했다면, 위 라인을 통해 편리하게
gemma-2b-it모델을 빠르게 로드해올 수 있다.AutoModelForCausalLM과AutoTokenizer는 Hugging Face의transformers라이브러리에서 제공하는 모델 및 토크나이저 선택을 위한 클래스이다. 매개 변수로 지정한 모델과 해당하는 토크나이저를 자동으로 선택하게 된다.
(2) 모델 사용해보기
[2 - 1] Gemma-2b-it 모델에 예시 질문하기
- Hugging Face에서 제공하는 Gemma2의 Model Card에, prompt를 어떻게 작성해야 하는지에 대한 정보가 담겨 있다.
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "google/gemma-2-2b-it"
dtype = torch.bfloat16
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype=dtype,)
# chat prompt
chat = [
{
"role": "user",
"content": "Write a hello world program"
},
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
model과 tokenizer를 받아오는 부분은 동일하고, 주목해야할 부분은 role, content를 키로 가지는 객체를 포함한 chat 리스트와 prompt이다.
apply_chat_template는 huggingface에서 제공하는 메서드로, chat의 리스트를 tokenzier가 사용하는 형태로 바꿔준다. gemma2가 아니라 다른 모델을 사용한다면 다른 형태로 파싱이 된다. How do I use chat templates? 참고
At this point, the prompt contains the following text:
<bos><start_of_turn>user
Write a hello world program<end_of_turn>
<start_of_turn>model
<bos>, begin of sequence로 시작하여 user인 내가 turn을 쓰고, 모델에게 turn을 넘기는 것이 gemma-2b-it의 prompt가 되겠다.text-generation을 위한 pipeline을 구축하고, pipe를 통해 질문(“Write a hello world program”)에 대한 답안을 받아보자.
# gemma2 에서 제공하는 파이프라인
pipe = pipeline("text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512
)
outputs = pipe(
prompt, # 위에서 만들어낸 prompt를 그대로 사용
do_sample=True, # 모델이 확률적으로 샘플링을 통해 텍스트를 생성하도록 설정
# temperature=0.2, # 확률분포의 평탄도, 낮은 값(0.2)은 모델이 더 결정적으로 응답을 생성하게 하고 높은 값은 응답이 더 무작위적으로 생성
# top_k=50, # 확률적으로 상위 50개의 단어만 고려하여 다음 단어를 샘플링하는 방식
# top_p=0.95, # 확률 분포에서 상위 95%에 해당하는 단어들만 선택되도록 설정
add_special_tokens=True # 모델이 특별 토큰을 처리할 수 있도록 설정
)
outputs[0]["generated_text"][len(prompt):] # print output
- pipe의 매개변수는 자유롭게 조정할 수 있을 것 같다.
[2 - 1] Gemma-2b-it의 예시 답안 확인하기
- 순정
gemma-2b-it모델이 출력해낸 답변은 아래와 같다.
print("Hello, world!")
This Python program will print the string “Hello, world!” to the console.
Explanation:
print()is a built-in Python function that prints the given argument to the console."Hello, world!"is the string that we want to print.\nis a newline character, which is added to ensure proper spacing.
How to run the program:
- Save this file as
hello_world.py(or any other name with a.pyextension). - Open a terminal window or command prompt.
- Navigate to the directory where you saved the file.
- Run the following command:
python hello_world.py
Output:
This command will execute the Python script and print the following output to the console:
Hello, world!
Note:
- The
print()function can take multiple arguments, which will be separated by commas. - You can use different formatting options in the
print()function, such asnameandvalueto format the output differently. ```
Write a hello world program은 다소 명확한 질문이어서 그런지, 꽤 좋은 답변을 남겨준다. 내 훈련 데이터셋에서는 어떨까? 아래의 프롬프트로 질문을 던져보았다.
<bos><start_of_turn>user\n
다음 글을 더 길게 써주세요:\n\n
對句의 영역은 다양하고, 그 원리는 짝짓기이다. 하나의 텍스트가 같은 분포도를 보이는 것은 자연스럽다
<end_of_turn>\n
<start_of_turn>model\n
- 대답은 아래와 같았다.
**더 긴 글:**
對句의 영역은 다양하고, 그 원리는 짝짓기이다. 짝짓기는 두 개의 문장을 서로 연결하는 어법으로,
하나의 텍스트가 같은 분포도를 보이는 것을 의미한다.
짝짓기는 문법적으로 정확한 연결어법이 아니지만, 자연스러운 표현을 만들기 위해 사용하는 일종의 문법적 표현이다.
짝짓기는 일반적으로 문장의 시작과 끝에 사용되는 경우가 많으며, 주로 서로 다른 분포를 보이는 문장을 연결하는 데 사용된다.
짝짓기는 문장의 구조를 변화시키거나, 주제와 내용을 강조하는 데 사용될 수 있다.
또한, 짝짓기는 특정 분포를 보여주는 문장을 표현하는 데 사용될 수 있다.
- 이미 훌륭한 답변이지만, 준비된 데이터셋을 통해 파인 튜닝함으로써 더 나은 답변을 생성하도록 하려는 것이 이번 프로젝트의 목표가 되겠다.
(3) 모델 파인튜닝 해보기
[3 - 1] Chat template 만들기
- 내 데이터셋의 summary와 original 문장 쌍을 이용해 prompt를 만들어주어야 한다. 아까 소개했던
tokenizer.apply_chat_template를 이용해도 괜찮지만 내가 참고한 블로그에서는<eos>토큰을 프롬프트의 끝에 붙여 추가적인 대화의 생성을 막고자 했고, 나도 그 방법이 옳은 것 같아 template을 만드는 generate prompt 함수를 따로 만들어주었다. 함수는 아래와 같다.
# 위에서 pandas Dataframe으로부터 만들었던 dataset을 매개변수로 받는다.
def generate_prompt(example):
prompt_list = []
for i in range(len(example['summary'])):
prompt_list.append(r"""<bos><start_of_turn>user
다음 글을 더 길게 써주세요:
{}<end_of_turn>
<start_of_turn>model
{}<end_of_turn><eos>""".format(example['summary'][i], example['original'][i]))
return prompt_list
- 데이터셋이 어떤 형태를 하고 있는지에 따라
generate_prompt함수의 생김새가 달라질 수 있을 것이라 생각한다. 다만 생성된 prompt는 대략 아래와 같은 형태의 문답을 리스트로 가져야 할 것이다.
print(generate_prompt(dataset)[0]) # 첫 번째 원소 확인
<bos><start_of_turn>user
다음 글을 더 길게 써주세요:
對句의 영역은 다양하고, 그 원리는 짝짓기이다. 하나의 텍스트가 같은 분포도를 보이는 것은 자연스럽다.<end_of_turn>
<start_of_turn>model
짐작할 수 있는 것처럼, 對句의 영역은 음운, 단어, 어구, 시편의 차원에서 다양하게 이뤄지고 있으며,
그 원리는 짝짓기이다. 하나의 텍스트는 음운으로부터 텍스트 자체까지에 이르는 위계적 양상을 보이므로
對句의 영역 또한 같은 분포도를 보이는 것은 퍽 자연스럽다. 문제는 텍스트의 전 영역에 걸쳐 짝을 만들어야
한다는 강박증이다. 왜 한시학은 짝짓기에 집착하는가?<end_of_turn><eos>
- 위의 저
<bos> ~ <eos>의 뭉치들로 학습을 진행할 것이다. 논문 초록의 요약본을 학습시켜주면, 새로운 주제에 대한 요약문을 던져주었을 때 새로운 초록을 생성할 수 있을 것이다. generate_prompt 함수와 dataset의 경우, 조금 있다 훈련을 진행할 때 만들 SFTTrainer 객체의 매개변수로 들어가게 된다.
[3 - 2] 양자화
- 참고한 블로그의 설정을 그대로 가져왔다.
lora_config = LoraConfig(
r=6, # 저차원 행렬의 랭크(rank) 정의
lora_alpha = 8, # LoRA에서 사용되는 스케일링(Scaling) 팩터
lora_dropout = 0.05, # 드롭아웃으로 과적합 방지
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
# LoRA 적용을 위한 모델 내의 특정 레이어(모듈) 지정
task_type="CAUSAL_LM", # task_type은 LoRA가 적용되는 작업의 유형을 지정함
# 여기서는 CAUSAL_LM(Causal Language Modeling)을 나타낸다.
)
bnb_config = BitsAndBytesConfig(
# 입력값을 4 bit로 변환
load_in_4bit=True,
# 모델을 4 bit으로 양자화
bnb_4bit_quant_type="nf4",
# 4 bit 계산에 사용될 데이터 유형, 4비트 부동소수점(bfloat16), 4비트 정수(uint8)
bnb_4bit_compute_dtype=torch.float16
)
사실 LLM을 개인이 온전히 다루기란 쉬운 일이 아니다. LoRA(Low-Rank Adaptation of Large Language Model)과 QLoRA(Quantized)는 그것을 가능하게 하는 혁신적인 기술이다. HuggingFace의 LoRA, QLoRA에 대한 설명을 참고하면 좋을 것 같다.
- Documentation: LoRA
- Documentation: QLoRA
LoRA (Low-Rank Adaptation of Large Language Models) is a popular and lightweight training technique that significantly reduces the number of trainable parameters. It works by inserting a smaller number of new weights into the model and only these are trained. This makes training with LoRA much faster, memory-efficient, and produces smaller model weights (a few hundred MBs), which are easier to store and share. LoRA can also be combined with other training techniques like DreamBooth to speedup training.
자세한 작동방식은 아직은 블랙박스이지만(나에게), 우선 모델에 새로운 가중치를 집어넣고 그것만을 훈련시키는 것으로 훈련량을 매우 크게 감소시키는 기술로 이해된다.
QLoRA는 모델을 양자화시킨 후, 거기에 LoRA 기술을 적용하는 것으로 더 적은 리소스로 학습을 진행할 수 있다고 한다
QLoRA를 적용하여 다시 모델을 로드한다.
model = AutoModelForCausalLM.from_pretrained(BASE_MODEL, device_map="auto", quantization_config=bnb_config)
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL)
tokenizer.padding_side = 'right'
[3 - 3] SFTTrainer 실행, 훈련
SFTTrainer(Supervised Fine-Tuning Trainer)는 인간 피드백을 통한 강화 학습(RLHF)을 위한 중요한 단계로, 사용하기 쉬운 API를 통해 단 몇 줄의 코드만으로 데이터셋을 훈련할 수가 있다.
공식문서를 참고하면 좋을 것 같다.
Document: Supervised Fine-Tuning Trainer
from transformers import EarlyStoppingCallback
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
# train_dataset=val_dataset,
max_seq_length=512,
args=TrainingArguments(
output_dir="/content/drive/MyDrive/Colab_Notebooks/Gemma2/write_my_paper_output/gemma_WriteMyPaper",
num_train_epochs = 1,
max_steps=5000,
per_device_train_batch_size=1, # 각 GPU마다 처리되는 샘플의 개수
gradient_accumulation_steps=4, # 늘리면 메모리가 줄어듬 (한 스텝에 batchsize * acc_steps = 8개 샘플 처리)
optim="paged_adamw_8bit",
warmup_ratio=0.03,
learning_rate=2e-4,
fp16=True, # fp16=True,
logging_steps=100,
# eval_strategy="steps", # 검증을 위한 평가 전략 설정
# eval_steps=1500, # 매 2000 스텝마다 검증 수행
# save_steps=1500, # eval_steps의 배수로 설정
# save_total_limit=1, # 체크포인트 저장 제한
# load_best_model_at_end=True, # 가장 성능 좋은 모델을 로드
# metric_for_best_model="eval_loss", # 최상의 모델을 선택할 때 사용할 지표
# greater_is_better=False, # 지표가 낮을수록 좋은 경우(예: 손실)
push_to_hub=False,
report_to=None,
),
peft_config=lora_config,
formatting_func=generate_prompt,
# callbacks=[EarlyStoppingCallback(
# early_stopping_patience=3, # patience: 개선이 없는 스텝 수
# early_stopping_threshold=0.01 # 개선으로 간주되는 최소 변화율
# )]
)
이 SFTTrainer를 조정하면서 많은 시행착오를 겪었다. 특히 early stopping 함수를 도입하기 위해 train-validation set으로 데이터셋을 분할하고,
eval_step마다 검증을 진행하려고 했으나 매개 변수를 어떻게 조정해도 반드시 메모리 에러가 발생했기 때문에 결국 그 부분은 없애고 데이터셋 전체를 train set으로 사용할 수 밖에 없었다. 이때 생긴 의문들을 해소하지 못하고 넘어간 게 아쉬움으로 남는 것 같다.팀원들의 피드백을 듣고 느낀건데, 결국 이 파인 튜닝 모델을 정량적으로(점수를 매긴다든지) 평가할 방법이 애매한데 어떻게 검증 스텝을 진행할 수 있는지 궁금해졌다. 이 부분에 대해선 더 많은 공부가 필요할 것 같다. 어쩌면 계속해서 메모리 부족 문제를 겪었던 이유가 이것과 관계가 있을지도 모르겠다.
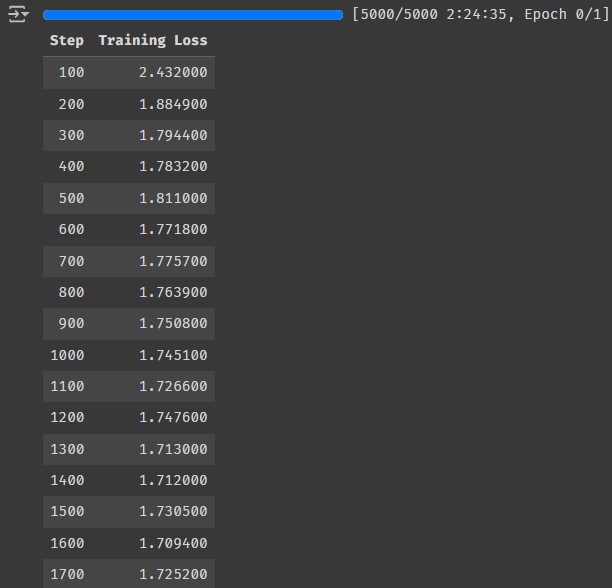
trainer.train()
- 훈련의 경우, Colab L4 GPU 기준 약 2시간 반 정도가 소요되었다.
훈련당2000원
(4) Hugging Face 배포 및 Test Code 작성
- 가장 마지막 checkpoint-5000(max_step 5000으로 훈련)의 모델을 Hugging Face에 배포하고, 그에 맞춰 Test Code를 작성하여 훈련되지 않은 새로운 데이터셋의 초록의 요약본을 가지고 새로운 초록을 작성하도록 해보고, Original 초록과 비교해보았다.
- gyopark/gemma-2-2b-it-WriteMyPaper 에서 배포한 모델의 모델 카드를 확인해볼 수 있다.
[4 - 1] 환경 설정 및 테스트 데이터셋 로드
- 훈련 코드를 작성할 때와 동일하게 환경 설정하고, 미리 준비해둔 테스트 데이터셋 json을 로드하였다.
test_path = '/content/drive/test_paper.json'
with open(test_path, 'r', encoding='utf-8') as f:
data = json.load(f)
# 데이터를 담을 리스트 초기화
documents = []
# 2. 데이터 파싱
for item in data[0]['data']:
doc = {
'category': item.get('ipc', ''),
'title': item.get('title', ''),
'summary': ' '.join([summary['summary_text'] for summary in item.get('summary_entire', [])]),
'original': ' '.join([summary['orginal_text'] for summary in item.get('summary_entire', [])])
}
documents.append(doc)
# 3. 데이터프레임으로 변환
df_test = pd.DataFrame(documents)
df_test.head()

- 테스트 세트의 랜덤한 summary와 original을 살펴보고, 그것을 가지고 질문한 뒤 대답을 확인해보자.
dataset_test[115]
‘summary’: ‘ 한ㆍ중ㆍ일 3국의 정치적 태도와 사회경제체제를 ‘세계가치관조사’ 자료를 이용하여 국가 간 비교분석하였다. 중국의 아시아적 가치 지향성이 가장 높고 일본이 가장 낮다. 서구적 민주주의 지향성은 일본이 가장 높고 한국이 그 다음이며 중국이 가장 낮다. 한ㆍ중ㆍ일 3국의 정치적 태도에서의 차이는 사회구조적 변동 경험을 반영하는 것이다. ‘,
‘original’: ‘이 연구는 한ㆍ중ㆍ일 3국의 정치적 태도와 사회경제체제를 ‘세계가치관조사’ 자료를 이용하여 국가 간 비교분석을 시도하였다. 중국의 아시아적 가치 지향성이 가장 높고 일본이 가장 낮으며 한국은 그 중간이다. 서구적 민주주의 지향성은 일본이 가장 높고 한국이 그 다음이며 중국이 가장 낮다. 중국인이 한국인과 일본인보다 상대적으로 자본주의 지향성이 높고 보수적인데 반해, 일본인은 개혁 지향적이고 한국인은 상대적으로 혁명 지향적이다. 한ㆍ중ㆍ일 3국의 정치적 태도에서의 이러한 차이는 그동안의 사회구조적 변동 경험을 반영하는 것이다. 중국에서 민주적 정치문화가 확산되고 있기는 하지만 중국의 정치지도자들이 민주주의의 이상을 추구하기보다는 실용적이고 기능적으로 민주주의에 접근하고 있는 한 중국의 정치적 민주화는 급격하게 단시일에 실현되기보다는 좀 더 시간이 필요할 것이다.’
- 내가 파인튜닝한 모델이 원본의 original처럼 정교한 문단을 생성할 수 있는지가 관건이겠다.
[4 - 2] Hugging Face Login 및 Finetuned Model 호출
- Hugging Face 로그인은 앞서와 같이 진행하면 되고, Hugging Face에 모델을 배포했기 때문에 그쪽을 통해 파인튜닝된 나의 모델을 불러올 수가 있다.
FINETUNED_MODEL = "gyopark/gemma-2-2b-it-WriteMyPaper" # 나의 모델
model = AutoModelForCausalLM.from_pretrained(FINETUNED_MODEL, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(FINETUNED_MODEL)
- 이후로는 일반적으로 모델에게 질문하듯이 pipeline을 만들고 output을 출력하면 된다.
[4 - 3] 질문 파이프라인 구축 및 대답 생성
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
) # gemma에서 제공하는 파이프라인이라고 한다.
messages = [
{
"role": "user",
"content": "다음 요약된 글을 한 문단으로 길게 써주세요.:\n\n{}".format(doc)
}
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
prompt
- 프롬프트는 아래와 같다.
<bos><start_of_turn>user
다음 요약된 글을 한 문단으로 길게 써주세요.:
한ㆍ중ㆍ일 3국의 정치적 태도와 사회경제체제를 ‘세계가치관조사’ 자료를 이용하여 국가 간 비교분석하였다.
중국의 아시아적 가치 지향성이 가장 높고 일본이 가장 낮다.
서구적 민주주의 지향성은 일본이 가장 높고 한국이 그 다음이며 중국이 가장 낮다.
한ㆍ중ㆍ일 3국의 정치적 태도에서의 차이는 사회구조적 변동 경험을 반영하는 것이다.
<end_of_turn>
<start_of_turn>model
outputs = pipe(
prompt,
do_sample=True,
add_special_tokens=True,
max_new_tokens=1024
)
outputs[0]["generated_text"][len(prompt):]
[4 - 4] 새로운 대답
- 파인튜닝된 모델을 통해 생성한 새로운 초록은 아래와 같다.
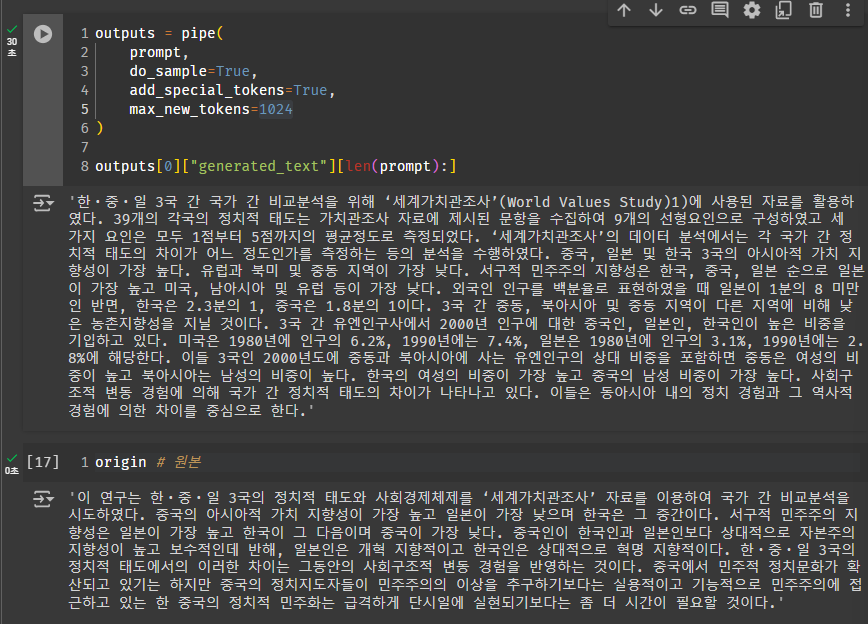
‘New Original’ : 한ㆍ중ㆍ일 3국 간 국가 간 비교분석을 위해 ‘세계가치관조사’(World Values Study) 1)에 사용된 자료를 활용하였다. 39개의 각국의 정치적 태도는 가치관조사 자료에 제시된 문항을 수집하여 9개의 선형요인으로 구성하였고 세 가지 요인은 모두 1점부터 5점까지의 평균정도로 측정되었다. ‘세계가치관조사’의 데이터 분석에서는 각 국가 간 정치적 태도의 차이가 어느 정도인가를 측정하는 등의 분석을 수행하였다. 중국, 일본 및 한국 3국의 아시아적 가치 지향성이 가장 높다. 유럽과 북미 및 중동 지역이 가장 낮다. 서구적 민주주의 지향성은 한국, 중국, 일본 순으로 일본이 가장 높고 미국, 남아시아 및 유럽 등이 가장 낮다. 외국인 인구를 백분율로 표현하였을 때 일본이 1분의 8 미만인 반면, 한국은 2.3분의 1, 중국은 1.8분의 1이다. 3국 간 중동, 북아시아 및 중동 지역이 다른 지역에 비해 낮은 농촌지향성을 지닐 것이다. 3국 간 유엔인구사에서 2000년 인구에 대한 중국인, 일본인, 한국인이 높은 비중을 기입하고 있다. 미국은 1980년에 인구의 6.2%, 1990년에는 7.4%, 일본은 1980년에 인구의 3.1%, 1990년에는 2.8%에 해당한다. 이들 3국인 2000년도에 중동과 북아시아에 사는 유엔인구의 상대 비중을 포함하면 중동은 여성의 비중이 높고 북아시아는 남성의 비중이 높다. 한국의 여성의 비중이 가장 높고 중국의 남성 비중이 가장 높다. 사회구조적 변동 경험에 의해 국가 간 정치적 태도의 차이가 나타나고 있다. 이들은 동아시아 내의 정치 경험과 그 역사적 경험에 의한 차이를 중심으로 한다.
- 아무래도 훈련된 데이터셋 내에서 새로운 summary인 한중일 3국의 세계 가치관 조사에 관한 정보를 긁어모아 새로운 Original 답안을 생성해낸 것 같다. 원본과 비교해서 보자.
‘original’: ‘이 연구는 한ㆍ중ㆍ일 3국의 정치적 태도와 사회경제체제를 ‘세계가치관조사’ 자료를 이용하여 국가 간 비교분석을 시도하였다. 중국의 아시아적 가치 지향성이 가장 높고 일본이 가장 낮으며 한국은 그 중간이다. 서구적 민주주의 지향성은 일본이 가장 높고 한국이 그 다음이며 중국이 가장 낮다. 중국인이 한국인과 일본인보다 상대적으로 자본주의 지향성이 높고 보수적인데 반해, 일본인은 개혁 지향적이고 한국인은 상대적으로 혁명 지향적이다. 한ㆍ중ㆍ일 3국의 정치적 태도에서의 이러한 차이는 그동안의 사회구조적 변동 경험을 반영하는 것이다. 중국에서 민주적 정치문화가 확산되고 있기는 하지만 중국의 정치지도자들이 민주주의의 이상을 추구하기보다는 실용적이고 기능적으로 민주주의에 접근하고 있는 한 중국의 정치적 민주화는 급격하게 단시일에 실현되기보다는 좀 더 시간이 필요할 것이다.’
- 생각보다 훨씬 괜찮은 답변이 생성된 것 같다. 약식으로 진행되었기 때문에 제대로 된 답변을 내놓지 못할 거라고 생각했는데, 팩트 체크만 어떻게 잘 하면 써먹을 수 있을지도 않을까하는 생각도 해본다. 물론 모델을 개선할 여지가 아주아주 많이 남아있겠지만 말이다…
(5) 마무리
이렇게 구글 머신러닝 부트캠프 2024의 Gemma Sprint 프로젝트를 마무리하였다. Andrew Ng 교수님의 LLM 강의는 정말 너무너무 어려워서 정신을 차릴 수가 없었기 때문에 Gemma Sprint도 너무너무 어려우면 어떡하나하고 걱정을 많이 했는데, 구글 선생님이 좋은 자료들을 많이 물어다줘서 생각보다는 수월하게 파인 튜닝을 진행할 수 있었다.
다만 메모리 문제 때문에 설정하고 싶었던 매개 변수를 마음껏 설정할 수 없었다는 점, 어디다가 물어보지 않고 gpt만 쓰면서 진행하느라 모르는 것을 속 시원하게 알기가 어려웠다는 점 정도가 아쉬웠다. Hugging Face에 레퍼런스가 잘 되어있기는 한데, 정제되어 있지가 않아서 원하는 정보만 골라내기가 어려웠었다.
그래도 부트캠프를 시작한 이후, 내 손으로 무언가 결과물을 낸 것 같아 뿌듯한 기분이다. Kaggle Competition의 경우 아직 이렇다 할 성과를 내지 못했는데, 이제 캐글에 전념해서 부트캠프를 잘 마무리할 수 있으면 좋겠다.